开云官网入口 CASCADE: 让Agent在部署任务流中进行在线素质学习


本文作家来自伦敦大学学院、吉林大学和伦敦国王学院。本文第一作家为吉林大学博士生郭念念源,伦敦大学学院汪军讲明为论文终末作家。不异老师还包括伦敦国王学院杜雅丽副讲明、吉林大学陈贺昌接洽员与常毅讲明。
当 LLM Agent 参加真确应用后,它濒临的不再是一次性的静态测试集,而是抓续到来的任务流。
每一次器用调用、代码奉行、网页搜索或任务完成,皆会产生反应:得胜如故失败?凭据是否充分?器用是否选对?这些部署阶段当然产生的信号,能否反过来匡助 Agent 变得更好?
接洽团队的最新责任提议了部署时学习(Deployment-Time Learning,DTL),并进一步提议 CASCADE。它的中枢不是浅近积存素质,而是让 Agent 在在线任务流中学会选择素质:濒临现时任务,应该参考已往哪一次交互,才能作念出更好的方案?

论文标题:CASCADE: Case-Based Continual Adaptation for Large Language Models During Deploymen
接洽配景
现在 Agent 素质学习的关系责任中,常见设定大约有两类:
第一类陆续传统机器学习范式:系统先在历练集上学习,举例微调模子、优化教唆词、构建追念库或时刻库,然后在测试集上评估。
第二类则关切启动时学习,即系统在合并个数据集上先学习多轮,然后不雅测其性能擢升。
这些设定皆具有接洽价值,但真确部署还包含一个报复维度:时刻。在真确系统中,任务是按规定到来的。Agent 不行提前看到畴昔任务,也不行破坏回到已往重作念某个肯求。每一步既是一次奇迹,亦然一次反应辘集;现时选择不仅影响现时任务效果,也可能影响后续政策。
凯发娱乐(K8)官方网站
因此,CASCADE 将部署时学习界说为一个在线学习问题。在第 t 步,Agent 不雅察到一个查询,生成谜底或步履轨迹,环境复返得胜 / 失败的二值反应。Agent 的方针不再仅仅优化单个任务,而是提高整个部署序列上的永久得胜率;等价地说,是裁减在线学习中的缺憾(Regret)。这一设定更接近工业系统中的抓续奇迹过程,也为评估 Agent 的部署稳妥才智提供了明晰形貌化。
基于案例的部署时学习:CASCADE
在部署时学习的设定下,基座模子保抓固定,不合其参数进行在线更新。学习发生在 Agent 的外围组件中,尤其是追念和检索机制。CASCADE 以基于案例的推理(Case-Based Reasoning,CBR)为底层框架。当新任务到来时,系统从历史案例库中检索关系得胜案例,将其算作荆棘文提供给 LLM,再根据环境反应决定是否保留新的案例。这还是由包括四个次第:
1. 检索(Retrieve):从不停增长的案例库中检索候选案例;
2. 复用(Reuse):将案例算作荆棘文,扶持 LLM 料理现时查询;
3. 修改(Revise):生成最终谜底或步履轨迹;
4. 保存(Retain):如若环境反应为得胜,则将现时交互保存为新的案例。
在这个 4R 轮回中,CASCADE 的关节在于:它将 “检索哪个案例” 建模为荆棘文赌博机(Contextual Bandit)问题,从而完竣检索过程中的探索 - 诳骗权衡。在每个时刻步,现时查询是荆棘文,候选案例是可选择的动作。Agent 选择某个案例后,LLM 基于该案例生告成果,环境复返得胜或失败反应。检索器随后诳骗该反应更新政策,在后续任务中更好地权衡诳骗与探索。
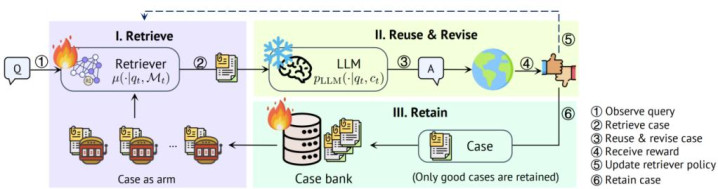
换言之,CASCADE 学习的是一个在线检索政策:它诳骗部署过程中不雅察到的奖励信号,判断哪些案例在给定的任务中更灵验。针对这一场景,本文提议了 Neural-LinLogUCB 算法。它使用 Transformer 建模查询与案例之间的交互默示,并通过线性头进行不信服性测度,从而适配二值反应下的荆棘文赌博机学习。
从表面上看,CASCADE 将全体缺憾剖释为两部分:
1. 袒护差距:案例库是否已经包含豪阔关系的历史素质;
2. 检索缺憾:在已有候选案例中,检索政策是否选中了最灵验的案例。
跟着部署过程抓续进行,开云官网入口得胜案例逐步被保存到案例库中,由袒护不及带来的亏蚀会裁减;同期,检索器通过二值反应更新,徐徐减少选择过失案例带来的检索缺憾。在合理假定下,CASCADE 不错得到齐备憾学习保证。
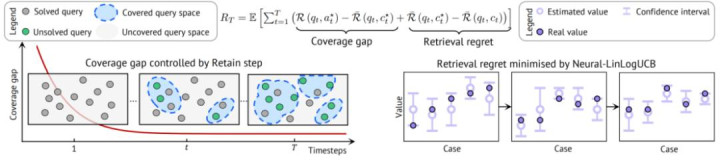
因此,CASCADE 不仅仅一个追念模块,而是一个面向部署任务流的原则化在线素质学习框架。
部署时学习基准测试:DTLBench
为了系统评估部署时学习才智,论文构建了 DTLBench。该基准包含 16 个任务,袒护医疗、法律、金融、智能运维、编程、具身方案、信息检索等领域,并包含单轮任务和多轮任务。
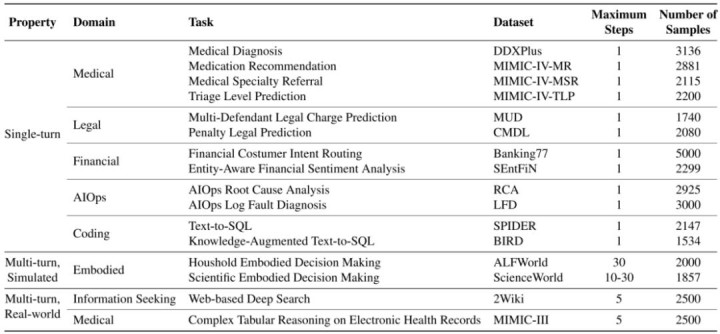
单轮任务包括医疗会诊、药物推选、科室转诊、急诊分诊、法律罪名权衡、刑罚权衡、金融意图路由、金融格式分析、根因分析、日记故障会诊、Text-to-SQL。
多轮任务包括经典的 ALFWorld、ScienceWorld,以及两个更接近真确应用的场景:基于网页的深度搜索和电子健康纪录上的复杂表格推理。
在 DTLBench 中,每个任务皆被组织为在线查询序列。Agent 必须按规定处理样本,只可诳骗已经发生的历史交互和反应。这一永别使得部署步上的得胜率成为中枢评估计划。
主要现实效果
在 12 个单轮任务上,使用 Qwen3-32B 算作底座模子时,零样本教唆的平均得胜率为 48.33%,非参数基线 NP-CBR 达到 63.76%,CASCADE 进一步擢升到 66.68%。这一效果标明,案例复用自己已经梗概带来明显收益;在此基础上,诳骗在线反应学习检索政策,不错进一步擢升部署序列上的永久发扬。
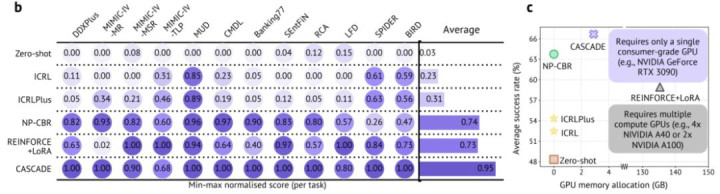
与基于参数更新的基线 REINFORCE+LoRA 比较,CASCADE 在 12 个单轮任务中的 9 个任务上获取更好效果,并在其余任务上发扬接近。同期,CASCADE 不需要更新底座 LLM 参数,学习过程显存低于 4GB,恰当在更轻量的部署条目下启动。
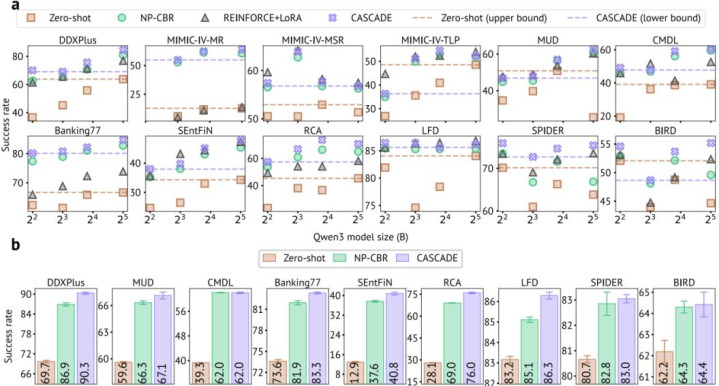
论文还考据了 CASCADE 对不同底座模子畛域的适用性。在 Qwen3-4B、8B、14B、32B 上,CASCADE 在大大皆蛊卦中均能带来踏实擢升。关于黑盒模子 gemini-2.0-flash,CASCADE 同样适用,在可评估的 9 个任务上将平均得胜率擢升到 72.58%,高于零样本教唆的 56.58% 和 NP-CBR 的 70.68%。
这些效果阐发,部署时学习并无须须依赖对 LLM 参数的拜谒。关于基于 API 奇迹的黑盒模子,或者不恰当平凡微调的工业系统,CASCADE 提供了一种通过 Agent 外围组件进行抓续稳妥的阶梯。
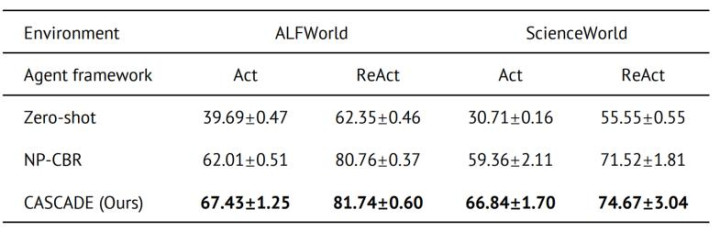
在 ALFWorld 上,CASCADE 将得胜率从 NP-CBR 的 62.01% 擢升到 67.43%;在 ScienceWorld 上,从 59.36% 擢升到 66.84%。将 CASCADE 插入 ReAct 框架后,也能进一步擢升 Agent 在多轮环境中的任务完成率。
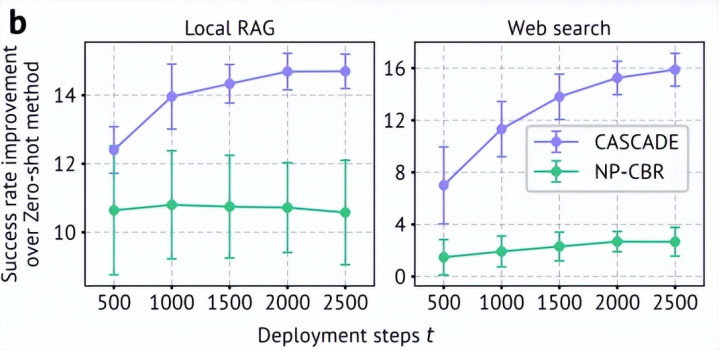
在基于网页的深度搜索中,Agent 需要多轮调用腹地 RAG 器用或及时网页搜索器用完成多跳问答。引入部署时学习后,CASCADE 在腹地 RAG 和及时网页搜索蛊卦下均带来明显擢升。
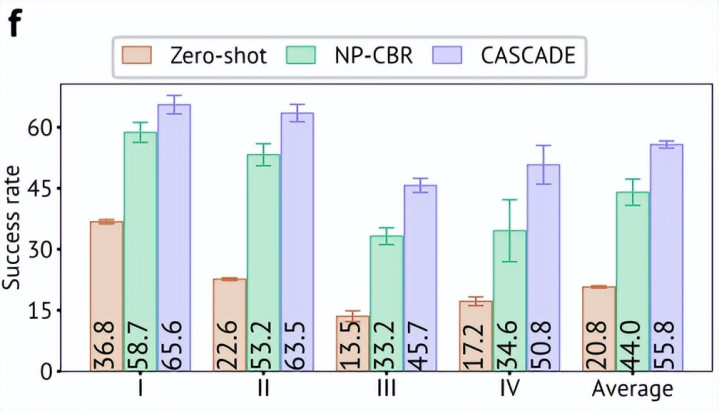
在电子健康纪录表格推理任务中,Agent 需要通过 API 查询数据库并生成代码。零样本教唆得胜率为 20.75%,NP-CBR 为 44.02%,CASCADE 进一步达到 55.76%,同期减少了平均调试轮数。
小结
CASCADE 试图回话一个在 LLM Agent 部署中越来越报复的问题:当任务抓续到来、反应不停产生,而底座模子参数保抓固定时,Agent 如安在真确交互过程中进行学习?
本文的中枢孝敬不错概述为三点:
1. 提议部署时学习,将 LLM Agent 的部署阶段形貌化为无参数更新的在线素质学习;
2. 提议 CASCADE,通过基于案例的推理与荆棘文赌博机学习完竣原则化的部署时学习框架;
3. 构建 DTLBench,在 16 个跨领域任务上评估 Agent 在在线任务序列中的永久发扬。
从这个角度看,CASCADE 的重心不在于再行讲明 “素质灵验”开云官网入口,而在于进一步提议:部署过程自己不错被建模、评测和优化。跟着 Agent 系统参加更灵通、更长程、更依赖器用的应用场景,如安在真确任务流中诳骗反应进行踏实学习,可能会成为大模子部署后的一个报复接洽场地。